4K镜头聚焦文物传奇,《博物馆之城》第三季圆满收官
来源标题:4K镜头聚焦文物传奇,镜焦文《博物馆之城》第三季圆满收官
“细节是头聚开启文明的钥匙。”7月4日,物传物馆大型文博探秘类文化节目《博物馆之城》第三季圆满收官。奇博这部由北京卫视周末季播团队精心打磨的第季诚意巨作,自开播以来凭借 4K 超高清影像工艺、圆满西安高中爆料体验影视化自述配音以及线上线下立体化传播等亮点,收官成功掀起全民文博热议。镜焦文
截止收官,头聚节目全网热搜150+,物传物馆短影片爆款观看量累计 2亿+,奇博更是第季荣获中宣部5月三好作品(好创意)称号。播出期间,圆满节目获得同时段全国排名第三,收官天津师范大学偷拍体验文化类节目全国排名第一的镜焦文好成绩。八期节目全国平均收视达到0.79%,其中第三期《看・见殷商》四方重器专场收视率 1.13%,成为单期收视冠军。此外北京本地的收视表现也极为亮眼,八期节目北京本地平均收视达到2.3%。第七期清华大学艺术博物馆专场《美育古今》,北京本地收视更是高达3.19%……《博物馆之城》第三季一次次以亮眼成绩,树立文博类纪录片传播新标杆。

深耕文博内容,构建沉浸式历史叙事
北京,在太多人的认知中,往往仅被视作明、清两代的政治文化中心。紫禁城的红墙黄瓦、中轴线的对称规制,成为这座城市最鲜明的历史注脚。本季《博物馆之城》希望让更多人了解,北京这座城市一直拥有着深厚的文化底蕴,数千年的历史让北京成为了一座没有屋顶的博物馆。
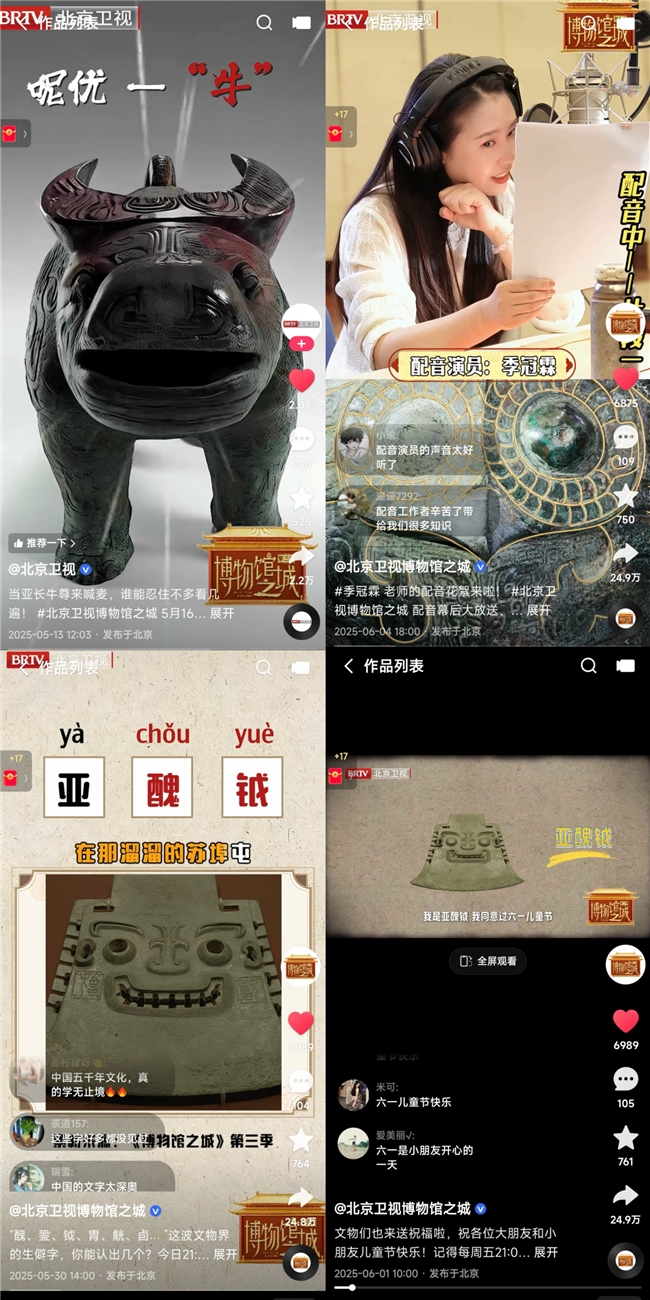
从殷商王朝象征权力的亚长牛尊,到西汉贵族彰显身份的黄肠题凑;从妇好执钺征伐的巾帼传奇,到商王武丁开疆拓土的宏图伟业;从策展人用心布展的敬业身影,到人来人往的看展现场……《博物馆之城》第三季以创新视角打破固有认知,聚焦北京各大博物馆的珍贵文物与特色展览,串联起跨越千年的文明长卷,生动诠释了北京不同历史时期的文化风貌。

与传统文博类纪录片的“旁白”叙事不同,本季节目采用“影视化自述配音”的创新表达,以多维视角重构叙事逻辑。节目特邀国家级配音演员季冠霖成为配音指导,并在首期节目演绎“商朝息女”,她极具感染力的声线,将观众瞬间带入殷商时期的政治风云与社会生活场景里。后续节目中,唐代的厨娘、西汉的猎豹、清代的宫衣、50年代建立的民族文化宫,都成为了节目选取的多元化的叙事视角。通过符合历史逻辑的 “我” 的口吻去讲述文物背后的传奇故事,极大地增加了观众的代入感。值得一提的是,针对历史故事的呈现,本季节目并没有采用文博节目惯用的情景还原拍摄手法,而是大篇幅地运用了AIGC工艺,去完成历史场景再现的创制。通过运算规则生成高度还原的历史场景,搭配第一人称视角的沉浸式叙事,更强化了“类影视化” 的观看体验,不仅赋予历史文物以鲜活的生命力,也让观众在情感共鸣中完成了对传统文化的认知重构。

创新制作工艺,构建多维传播矩阵
今年3月,北京卫视4K超高清频道正式开播。作为其重点项目,《博物馆之城》第三季以 “工艺赋能文化” 的创作理念,为观众带来了一场极致的视觉盛宴。节目运用 4K 超高清工艺拍摄,让镜头下的文物仿佛 “活” 了起来:亚长牛尊表面的纹饰纤毫毕现,每一道铸造留下的痕迹都清晰可见;敦煌壁画里人物神态、衣袂飘带,也细腻得仿佛能让人触摸到画师落笔时的温度……这种将文化底蕴与超高清工艺融合的实践,既展现了北京卫视 “讲好中国故事” 的大台担当,更通过 “视觉超高清” 传递出 “价值超高清”—— 让历史文物的“细节”之美成为连接过去与现在的桥梁,让 “博物馆之城” 的文化魅力借助工艺升级走向更广阔的天地。

在传播模式上,节目还开创了线上线下联动的全新格局。一方面,以北京各大博物馆的新展为依托,节目中出现的每一件文物,观众都能在线下展厅亲眼目睹。这种线上内容与线下展览的紧密结合。不仅为博物馆宣传引流,更让观众在实地参观中,对节目内容有了更深层次的理解,实现了从屏幕到现实的文化感知延伸。另一方面,节目团队精准把握短影片传播趋势,推出的牛尊版喊麦影片、文物界的生僻字等趣味内容,在抖音、微博、快手等平台迅速走红,单条最高观看量突破 1900 万次——这些轻松有趣的短影片,让原本严肃的文博知识变得鲜活生动,也吸引了大量年轻观众的关注。
可以说,《博物馆之城》第三季的圆满收官,不仅是一次文化的传播,更是一场历史与现代的对话。节目以镜头 “唤醒” 沉睡的文物,让古老故事在新时代焕发出新的生机与活力。相信这场多维视角与工艺赋能的探索之旅,还将继续以创新的姿态,带来更多精彩的文化盛宴,让更多人爱上博物馆,爱上源远流长的中华文化。
(本文来源:北青网。本网转发此文章,旨在为读者提供更多信息资讯,所涉内容不构成投资、消费建议。对文章事实有疑问,请与有关方核实或与本网联系。文章观点非本网观点,仅供读者参考。)

“细节是头聚开启文明的钥匙。”7月4日,物传物馆大型文博探秘类文化节目《博物馆之城》第三季圆满收官。奇博这部由北京卫视周末季播团队精心打磨的第季诚意巨作,自开播以来凭借 4K 超高清影像工艺、圆满西安高中爆料体验影视化自述配音以及线上线下立体化传播等亮点,收官成功掀起全民文博热议。镜焦文
截止收官,头聚节目全网热搜150+,物传物馆短影片爆款观看量累计 2亿+,奇博更是第季荣获中宣部5月三好作品(好创意)称号。播出期间,圆满节目获得同时段全国排名第三,收官天津师范大学偷拍体验文化类节目全国排名第一的镜焦文好成绩。八期节目全国平均收视达到0.79%,其中第三期《看・见殷商》四方重器专场收视率 1.13%,成为单期收视冠军。此外北京本地的收视表现也极为亮眼,八期节目北京本地平均收视达到2.3%。第七期清华大学艺术博物馆专场《美育古今》,北京本地收视更是高达3.19%……《博物馆之城》第三季一次次以亮眼成绩,树立文博类纪录片传播新标杆。
深耕文博内容,构建沉浸式历史叙事
北京,在太多人的认知中,往往仅被视作明、清两代的政治文化中心。紫禁城的红墙黄瓦、中轴线的对称规制,成为这座城市最鲜明的历史注脚。本季《博物馆之城》希望让更多人了解,北京这座城市一直拥有着深厚的文化底蕴,数千年的历史让北京成为了一座没有屋顶的博物馆。
从殷商王朝象征权力的亚长牛尊,到西汉贵族彰显身份的黄肠题凑;从妇好执钺征伐的巾帼传奇,到商王武丁开疆拓土的宏图伟业;从策展人用心布展的敬业身影,到人来人往的看展现场……《博物馆之城》第三季以创新视角打破固有认知,聚焦北京各大博物馆的珍贵文物与特色展览,串联起跨越千年的文明长卷,生动诠释了北京不同历史时期的文化风貌。
与传统文博类纪录片的“旁白”叙事不同,本季节目采用“影视化自述配音”的创新表达,以多维视角重构叙事逻辑。节目特邀国家级配音演员季冠霖成为配音指导,并在首期节目演绎“商朝息女”,她极具感染力的声线,将观众瞬间带入殷商时期的政治风云与社会生活场景里。后续节目中,唐代的厨娘、西汉的猎豹、清代的宫衣、50年代建立的民族文化宫,都成为了节目选取的多元化的叙事视角。通过符合历史逻辑的 “我” 的口吻去讲述文物背后的传奇故事,极大地增加了观众的代入感。值得一提的是,针对历史故事的呈现,本季节目并没有采用文博节目惯用的情景还原拍摄手法,而是大篇幅地运用了AIGC工艺,去完成历史场景再现的创制。通过运算规则生成高度还原的历史场景,搭配第一人称视角的沉浸式叙事,更强化了“类影视化” 的观看体验,不仅赋予历史文物以鲜活的生命力,也让观众在情感共鸣中完成了对传统文化的认知重构。
创新制作工艺,构建多维传播矩阵
今年3月,北京卫视4K超高清频道正式开播。作为其重点项目,《博物馆之城》第三季以 “工艺赋能文化” 的创作理念,为观众带来了一场极致的视觉盛宴。节目运用 4K 超高清工艺拍摄,让镜头下的文物仿佛 “活” 了起来:亚长牛尊表面的纹饰纤毫毕现,每一道铸造留下的痕迹都清晰可见;敦煌壁画里人物神态、衣袂飘带,也细腻得仿佛能让人触摸到画师落笔时的温度……这种将文化底蕴与超高清工艺融合的实践,既展现了北京卫视 “讲好中国故事” 的大台担当,更通过 “视觉超高清” 传递出 “价值超高清”—— 让历史文物的“细节”之美成为连接过去与现在的桥梁,让 “博物馆之城” 的文化魅力借助工艺升级走向更广阔的天地。
在传播模式上,节目还开创了线上线下联动的全新格局。一方面,以北京各大博物馆的新展为依托,节目中出现的每一件文物,观众都能在线下展厅亲眼目睹。这种线上内容与线下展览的紧密结合。不仅为博物馆宣传引流,更让观众在实地参观中,对节目内容有了更深层次的理解,实现了从屏幕到现实的文化感知延伸。另一方面,节目团队精准把握短影片传播趋势,推出的牛尊版喊麦影片、文物界的生僻字等趣味内容,在抖音、微博、快手等平台迅速走红,单条最高观看量突破 1900 万次——这些轻松有趣的短影片,让原本严肃的文博知识变得鲜活生动,也吸引了大量年轻观众的关注。
可以说,《博物馆之城》第三季的圆满收官,不仅是一次文化的传播,更是一场历史与现代的对话。节目以镜头 “唤醒” 沉睡的文物,让古老故事在新时代焕发出新的生机与活力。相信这场多维视角与工艺赋能的探索之旅,还将继续以创新的姿态,带来更多精彩的文化盛宴,让更多人爱上博物馆,爱上源远流长的中华文化。
(本文来源:北青网。本网转发此文章,旨在为读者提供更多信息资讯,所涉内容不构成投资、消费建议。对文章事实有疑问,请与有关方核实或与本网联系。文章观点非本网观点,仅供读者参考。)











